
You can put a Softmax in front of CrossEntropyLoss. PyTorch won’t stop you. Here are 16 other architecture bugs it won’t catch.
A walkthrough of the 17-rule design-time linter inside Neurarch: what each rule catches, why it matters, and where static analysis stops being useful for neural networks.

The bug that started this
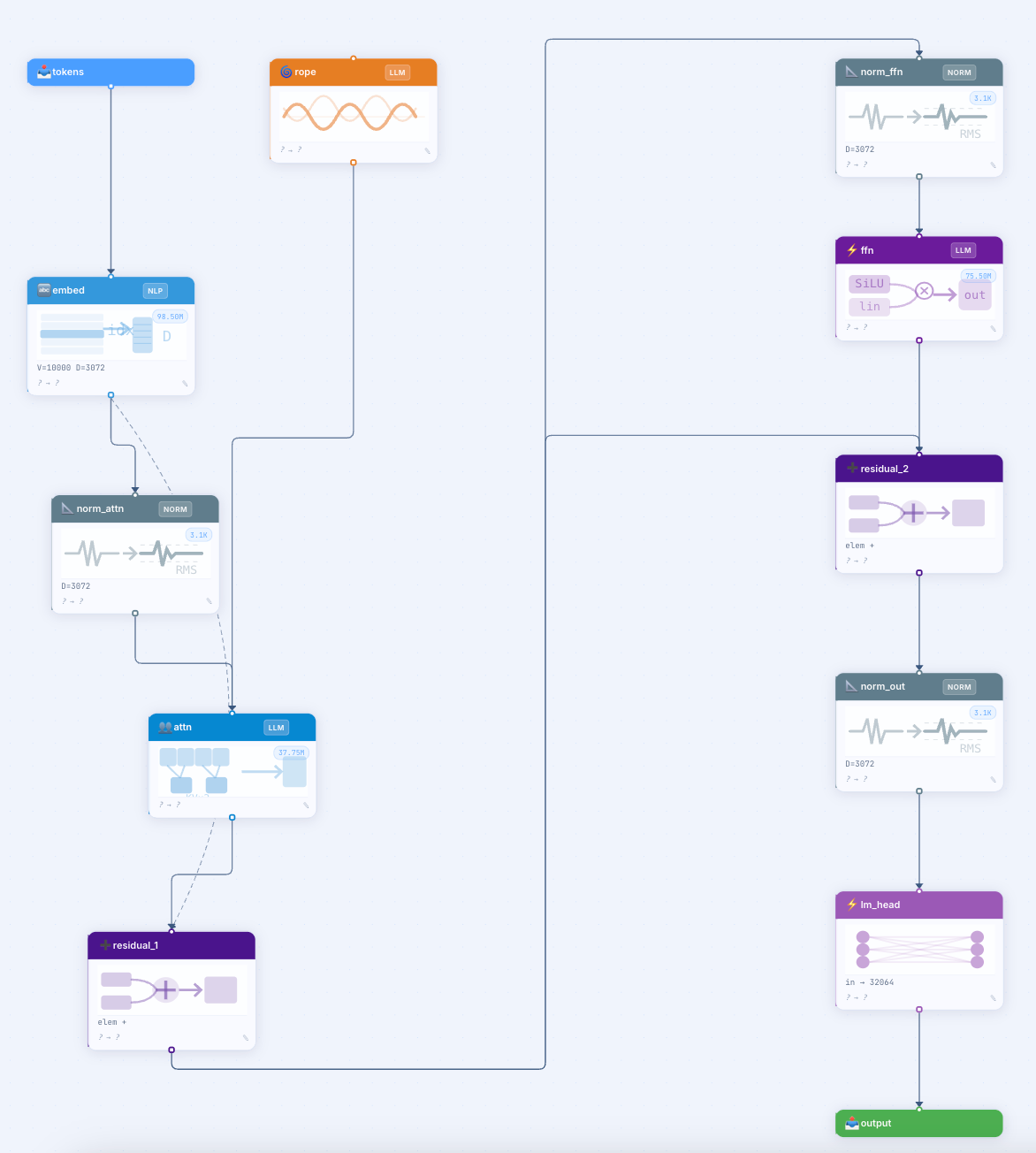
You can put a Softmax in front of CrossEntropyLoss in PyTorch. The model trains. The loss curve looks fine. You ship it. Accuracy is bad, and you spend the next day finding out why.
The bug is that nn.CrossEntropyLoss applies log-softmax internally, so the explicit Softmax causes double-application and degrades training stability. The bug is visible from the architecture diagram in two seconds. The framework only complains at runtime, after you have burned the GPU time and the morning.
This is one of 17 structural failure modes I built a design-time linter to catch. The rest cover normalization ordering, missing residuals in deep nets, attention without positional encoding, GQA head divisibility, SwiGLU dimension conventions, and a dozen more. This post walks through what each rule catches, why it matters, and where static analysis stops being useful.
Why a linter at all
Every existing PyTorch tool catches structural bugs after the fact. Shape errors only fire when you call forward(). Vanishing gradients show up as flat loss curves after the training loop. NaN losses appear on an A100 you have already paid for. The pattern is consistent: the bug was visible from the graph, but the framework only flagged it at runtime, and the cost was hours of GPU plus the mental tax of figuring out which of 200 layers broke the gradient.
I wrote a linter that runs on the architecture graph at design time, before any forward pass. Static analysis for neural networks. Today it ships with 17 rules.
The 17 rules, grouped
The rules fall into five categories, each tied to a class of common failure mode.
Structure (4 rules) — the graph itself is malformed
R01 — Model has no Input node
R02 — Model has no Output node
R03 — Isolated components with no connections in or out
R04 — Dead-end: a non-output layer that has inputs but no outputs
These four catch the kind of bug you make when you delete a layer mid-edit and forget to reconnect. Most code generators silently drop disconnected nodes, so you only notice when the generated PyTorch file is mysteriously short.
Ordering (4 rules) — layers are in the wrong sequence
R05 — Normalization placed after an activation (the conventional pre-activation order is Conv → Norm → Activation)
R06 — Dropout directly before BatchNorm (BN re-normalizes the random zeros Dropout introduces, cancelling most of its regularization)
R07 — Softmax or Sigmoid immediately before Output (PyTorch’s
nn.CrossEntropyLossapplies log-softmax internally, so an explicit Softmax causes double-application and degrades training stability)R08 — Any normalization immediately before Output (normalizing raw logits constrains the output range and breaks standard loss functions)
R07 is the rule I personally hit the most. Every ML engineer learns the lesson once. The linter just keeps you from learning it again every six months.
Pattern (4 rules) — the architecture is missing a structural ingredient
R09 — Network deeper than 8 conv/linear layers with no residual connections at all
R10 — Attention layers present but no positional encoding anywhere (attention is permutation-invariant; without position info the model cannot distinguish token order)
R11 — Sigmoid or Tanh used in networks deeper than 5 layers (these saturate, and their gradient approaches zero for large inputs, halting learning in early layers)
R12 — Network deeper than 7 non-I/O layers with no normalization of any kind
These are the rules that turn into the “why is my loss curve flat” moment. None of them are individually subtle. What is subtle is that you only notice them collectively, after the training run.
Performance (2 rules) — the architecture trains but inefficiently
R13 — Dropout with
p > 0.65(rates above this introduce so much noise the model cannot learn stable representations)R14 — Activation tensor larger than 50M elements (~200 MB per sample at float32; at batch size 32 a single such layer needs 6.4 GB of activation memory)
R14 is the one that catches you trying to run a model on a 16 GB T4 that should really be on an A100.
Transformer-specific (3 rules) — the new wave of LLM architectures
R15 — MoE layer present without a reminder to add the auxiliary load-balancing loss in the training loop (MoE collapses without it, all tokens routing to one expert)
R16 — Grouped-Query Attention where
numHeadsis not divisible bynumKVHeads(the head grouping arithmetic literally does not work)R17 — SwiGLU
intermediateSizethat does not follow the LLaMA convention⌊(8/3 × D) / 256⌋ × 256(you get worse training dynamics and weird parameter counts)
R17 is the niche one. It will only ever fire for someone building a Llama-style decoder block from scratch. But for that one engineer, on that one architecture, it saves a week of “wait, why is my model 1.4× the parameter count of LLaMA-3-8B.”
The five most interesting rules to talk about
Five of the 17 rules are worth explaining in a bit more depth, because each one captures a class of failure that I have personally seen waste days.
R05 (Normalization after activation) is interesting because the wrong order trains. The model converges, the loss goes down, you ship. Six months later you read the BatchNorm paper again and realize you have been leaving accuracy on the floor for half a year. The linter catches it before you wire the connection.
R06 (Dropout before BatchNorm) is the same shape of failure. The model trains. The regularization just is not doing what you think it is. The fix is reordering to Conv → BN → Activation → Dropout. The linter knows this convention; you do not have to remember it.
R09 (Deep network without residuals) is the most expensive failure mode the linter catches. A 30-layer feedforward MLP with no skip connections will train to ~chance accuracy on anything non-trivial. The training run looks the same as a correct architecture for the first 10 minutes. The linter fires the moment you place the 8th deep layer without a residual in the graph.
R10 (Attention without positional encoding) catches the bug where someone copies the body of a Transformer block but forgets to add the embedding layer. The model technically trains, but it cannot use word order. The output is bag-of-words quality. You only notice when the BLEU score is awful.
R16 (GQA head mismatch) is the most “this is what static analysis is good for” rule. The arithmetic literally cannot work. numHeads = 32 and numKVHeads = 6 means each KV head serves 5.33 query heads, which is undefined. PyTorch will raise a shape error at runtime, but only after you have spent 20 minutes setting up the rest of the training script.
What this linter does not catch
A few classes of failure are out of scope for any static analyzer on a neural network graph.
It does not predict whether your loss will converge. That depends on initialization, learning rate, data, and optimizer choice, none of which are visible from the graph.
It does not catch shape mismatches that depend on dynamic input dimensions (e.g., variable sequence lengths in attention). It does forward-propagate the static type system through the DAG and catch many shape errors at design time, but a runtime shape error from a non-static dimension is still possible.
It does not know whether your task is the right task for the architecture you have drawn. A vanilla CNN can be structurally clean and totally wrong for natural-language modeling.
The rules are heuristics, not proofs. R09 will fire on a 9-layer Conv that genuinely does not need residuals (some short ResNet variants). R11 will fire on a deep GAN generator using Tanh as the output activation, where Tanh is correct. Treat the warnings as a checklist a senior engineer would walk through with you, not as a compiler error.
Why this lives inside an agent
The linter on its own is a list of warnings. What makes it useful in practice is that the AI agent can read the entire Architecture Health section as part of its context and emit structured fix actions, one per issue. The agent does not write PyTorch code to fix the bugs; it emits typed actions like {"type":"add_component","componentType":"add","afterName":"conv_8"} against a strict schema.
This is the same pattern I used at AWS to ship an agentic LLM that converted natural-language cloud requirements into validated AWS architecture diagrams: structured output against a typed schema, rather than free-form generation that the system has to parse. The architecture is the canonical artifact. Code is the derived view.
I will write that one up separately. The short version: typed-schema function-calling generalizes well to any domain where the artifact is a typed graph.
Try it
The linter ships with Neurarch (neurarch.com, free to try after signing in). Open the canvas, drag layers, watch warnings appear in the side panel as you place them. Ask the agent “fix issues” and it will walk the health list, emitting one targeted action per warning.
The full rule source is in architectureAdvisor.ts (feedback repo: github.com/neurarch-ai/neurarch-feedback — file issues, see roadmap, request new rules).
If you have a structural failure mode you have personally hit that is not in the 17 above, I want to hear about it. Best rule requests so far: shared-weight contract validation across siamese architectures (in progress), and gradient-checkpointing placement analysis for memory-constrained training (queued).
It is live and free to try. I would love feedback from anyone who has debugged a structural ML bug the hard way.